Краулер (поисковый бот, робот, паук) — это неотъемлемая для поисковой системы программа, отвечающая за поиск сайтов и сканирование их содержимого путем перехода по страницам и ссылкам для занесения собранной информации в базу данных поисковика.
Допустим, есть пользователь Иван Иванов, ежедневно посещающий какой-нибудь популярный книжный онлайн-ресурс, и этот ресурс регулярно пополняется новыми произведениями. Переходя на сайт, Иван осуществляет следующую последовательность действий:
- Заходит на главную страницу.
- Переходит в раздел «Новые книги».
- Просматривает список с недавно добавленными материалами.
- Открывает ссылки с заинтересовавшими его
заголовками. - Ознакомляется с аннотациями и скачивает
интересующие его файлы.
Чтобы найти подходящий материал, Иванову пришлось потратить около 10 минут. Если каждый день уделять 10 минут на поиск нужной книги, в месяц на этой уйдет в общем 5 часов. И это касается только одного сайта.
Во избежание таких временных затрат нужно использовать программу, в автоматическом режиме занимающуюся поиском новинок.
Без роботов ни один поисковик не будет эффективным, вне зависимости от того, Google это или новая поисковая система. И чтобы не делать, как Иван, они используют роботов для «обхода» сайтов, отыскивающих для поисковых систем новую информацию, которую они смогут предложить пользователям. И чем лучше и быстрее краулер сканирует страницы, тем актуальнее материалы находятся в выдаче поисковой системы.
Основные боты выполняют следующие функции:
- Собирают новый или обновленный контент с веб-ресурсов. Сканированием свежих публикаций и ранее размещенных статей занимаются пауки первого порядка.
- Идентификация зеркал. Краулер отыскивает сайты, содержащие идентичный контент, но с разными доменами. Подобные боты имеет Яндекс.
- Сканирование графических файлов. Для поиска графики может быть привлечен отдельный робот.
И много других различных краулеров, которые имеют свое предназначение, о которых мы поговорим ниже.
Виды краулеров
У каждого поисковика есть набор собственных веб-пауков, выполняющих различные функции. Поговорим о ботах двух популярнейших поисковых машин.
Роботы Яндекса
- YandexBot – основной краулер, занимающийся индексацией.
- YandexImages – вносит в индекс изображения ресурсов.
- YandexMobileBot – собирает страницы для их анализа и определения адаптации для смартфонов.
- YandexDirect – сканирует данные о материалах ресурсов-партнером РСЯ.
- YandexMetrika – поисковый паук сервиса Яндекс.Метрика.
- YandexMarket – бот Яндекс.Маркета.
- YandexCalenda – краулер Яндекс.Календаря.
- YandexScreenshotBot – делает скриншоты документов.
- YandexMedia – индексатор мультимедийных данных.
- YandexVideoParser – робот для видео.
- YandexPagechecker – отображает микроразметку.
- YandexOntoDBAPI – паук объектного ответа, который скачивает изменяющиеся данные.
- YandexAccessibilityBot – скачивает документы и проверяет, имеют ли к ним доступ пользователи.
- YandexSearchShop – скачивает файлы формата Yandex Market Language, которые относятся к каталогам товаров.
- YaDirectFetcher – собирает страницы, содержащие рекламу, с целью проверки их доступности для пользователей и анализа тематики.
- YandexirectDyn – создает динамические баннеры.
Боты Google
- Googlebot – главный индексатор контента страниц не только для ПК, но и адаптированных под мобильные устройства.
- AdsBot-Google – анализирует рекламу и оценивает ее качество на страницах, оптимизированных под ПК.
- AdsBot-Google-Mobile – выполняет аналогичные функции, что и предыдущий, только предназначен для мобильных страниц.
- AdsBot-Google-Mobile-Apps – работает также, как и стандартный AdsBot, но оценивает рекламу в приложениях, предназначенных для устройств на базе операционной системы Android.
- Mediaparnters-Google – краулер маркетинговой сети Google AdSense.
- APIs-Google – юзер-агент пользователя APIs-Google для отправки пуш-уведомлений.
- Googlebot-Video – вносит в индекс видеофайлы, содержащиеся на страницах ресурсов.
- Googlebot-Image – индексатор изображений.
- Googlebot-News – сканирует страницы с новостями и добавляет их в Google Новости.
Другие поисковые роботы
Краулеры есть не только у поисковых систем. Так, у популярной соцсети Facebook роботы собирают коды страниц, которые репостят пользователи, чтобы показывать ссылки с заголовками, описанием и картинкой. Рассмотрим более детально веб-пауков, не относящихся к поисковым системам Google и Яндексу.
Keys.so
Самый популярный инструмент в России для SEO-продвижения, который помогает анализировать ссылочную массу и ключевые запросы по которым показываются страницы сайтов. Что делает:
- изучает обратные ссылки;
- проводит мониторинг конкурентов;
- анализирует ранжирование страниц по запросам из Wordstat Yandex;
- проверяет сайты, недействительные ссылки;
- анализирует контекстную рекламу в выдаче;
- изучает ключевые слова, фразы и многое другое.
Благодаря нему специалисты в области цифрового маркетинга могут проанализировать своих конкурентов и подобрать наиболее эффективную тактику продвижения сайта.
Megaindex
Еще один отличный сервис для оптимизации сайтов, который имеет много данных для аналитики. Он решает такие задачи:
- создание качественного списка ключевиков;
- идентификацию и исправление ошибок на сайте;
- мониторинг и анализ отчетов;
- анализ ссылочной массы;
- поиск факторов, негативно влияющих на SEO;
- увеличение целевой аудитории и многое другое.
SEO Spider
Программа для сканирования данных на маленьких и крупных ресурсах. На ее основе вы примерно можете понять, как поисковые системе обходят URL сайта. Способна:
- находить повторяющиеся материалы;
- объединяться с аналитикой от Google;
- отыскивать битые ссылки;
- обрабатывать большой список ссылок;
- осматривать элементы страниц отдельно для каждого URL;
- изучать краулеры и другие директивы.
Spider работает на оперативных системах Windows, MacOS и Ubuntu. В бесплатной версии можно анализировать до 500 страниц.
Как управлять поисковым роботом
Очень часто приходится ограничивать доступ некоторым краулерам к определенным страницам сайта. Для этого существуют специальные правила, которые вебмастера и SEO-специалисты прописывают для пауков, чтобы они их придерживались. Указываются они в файле robots.txt.
Попадая на сайт, роботы сначала сканируют информацию в файле со списком документов, запрещенных для обхода, например, личные данные зарегистрированных пользователей. Ознакомившись с правилами, краулер или уходит с сайта, или начинает индексировать ресурс обходя стороной запрещенные URL и директории.
Что прописывать в файле robots:
- разделы сайта или фрагменты контента, закрытых/открытых
для пауков; - интервалы между запросами роботов.
Команды можно адресовать как всем ботам сразу, так и каждому по-отдельности.
Например, разберем такие записи в файле robots.txt:
User-agent: *
Disallow: /about.html
Disallow: /images/*
Allow: /images/$
User-Agent: Twitterbot
Allow: /imagesОпределим, что все это значит:
- Страница about.html закрыта от всех краулеров.
- Роботам твиттера разрешено сканировать все урлы, в адресе которых содержится /images.
- Остальным поисковым паукам разрешено посещать страницы, которые заканчиваются на /images (Allow: /images/$), но глубже переходить нельзя (Dissallow: /images/*).
Как узнать что робот заходил на сайт
Есть несколько способов вычислить, что краулер посещал сайт и какие именно страницы. Все зависит от того, чей это бот.
Поисковый робот Яндекса
Основной паук поисковика, индексирующий контент, посещает страницы веб-ресурсов и отсылает их в базу данных с завидной регулярностью. Но он может найти не все необходимые страницы сайта, если они например недоступны.
В Яндекс.Вебмастере вы можете с легкостью узнать, какие именно страницы обошел бот, чтобы отыскать URL недоступных для него страниц по причине перебоев на сервере или неправильного содержимого.
Зайдите в панели управления Вебмастера на страницу Индексирование, а затем – Статистика обхода. Обновление данных проводится ежедневно, максимум через 6 часов с той поры, когда робот зашел на страницу.
Изначально на сервисе вы увидите информацию по всему ресурсу. Если же вам нужна информация по определенному разделу, кликните на него в списке, расположенного в поле с указанным адресом сайта. Разделы выстроены в соответствии со структурой ресурса. Если вы не нашли в списке нужную страницу, сообщите о них поисковику через переобход страниц.
Другие роботы
Еще один отличный способ вычислить, что поисковый паук посещал сайт — заглянуть в логи сервера.
В них хранится вся информация касательно того, кто посещал ресурс, когда и по каким страницам переходил, какой у него IP-адрес, какой ответ получил на сайте и прочее. Читать логи вручную довольно трудно, поэтому есть специальные программы, помогающие анализировать и читать логи в удобном формате, что очень важно, потому что с их помощью вы видите любое посещение роботом и человеком.
Одним из самых популярных инструментов, используемых с данной целью, является Screaming Frog SEO Log File Analyser. Отмечу, что программа платная. Есть и бесплатная версия с ограниченным функционалом:
- Можно добавить лишь один сайт.
- Журнал событий содержит не более 1000 строк.
- Нет бесплатной техподдержки.
Пользоваться программой просто. Для начала потребуется найти файлы access.log на сервере и загрузить их на компьютер с помощью FTP. В большинстве случаев они располагаются в папке /access_logs/ или просто /logs/. Если вы хотите детально проанализировать историю посещений, скачайте логи за период не менее месяца. Скачав файлы, кликните по Import и выберите пункт Log file.
Затем, как данные загрузятся, укажите любое название проекта и укажите часовой пояс. Далее отобразится главное окно админки, где показывается подробная информация: какие краулеры посещали ресурс, с какой частотой, сколько страниц просматривали и так далее.
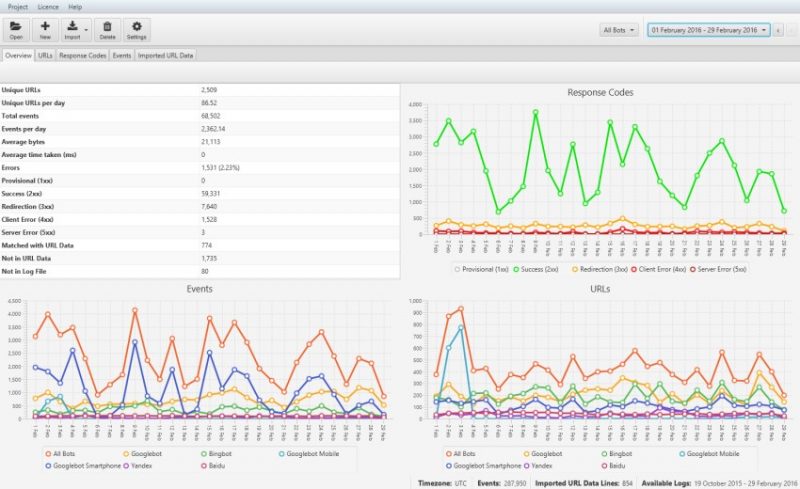
Но можно «копнуть» еще глубже. К примеру, узнать, какие УРЛы загружаются медленно, а с каких часто приходят на сайт. Помимо этого показывается информация о кодах ответов, отдаваемых ссылками. В меню Response Codes есть фильтр для группирования адресов по типу кода. Так вы очень быстро отыщите ошибки.
Кстати, если нажать правой кнопкой на ссылку, то можно:
- проверить ее на наличие в индексе поисковиков Google, Bing и Yahoo;
- узнать внешние ссылки, ведущие на нее;
- открыть ссылку в robots.txt;
- открыть в браузере или скопировать ее.
Особенно удобные функции перехода в файл robots и проверки сканирования.
Выводы
Без краулеров не существовало бы и поисковиков, ведь именно они сканируют сайты, собирают в них информацию и отправляют ее в базу данных, чтобы затем система включила ее в свой поиск и предоставила пользователям.
Поисковые боты нужны не только поисковикам, но и самим вебмастерам, чтобы успешно анализировать ресурсы, исправлять слабые места и успешно их раскручивать для поднятия на верхние позиции результатов выдачи.
Вопросы и ответы про краулеры
Собрал список вопросов про поисковых роботов, которые мне часто задают на консультациях по SEO. Привожу краткие ответы.

Приветствую!
Действительно полезная статья о поисковых роботах и не только. Сразу стало многое понятнее. Теперь не буду думать, что это за Семруш по моему сайту бегает 🙂